
Hadoop集群上运行mapreduce
作者:Zhan-bin
日期:2018-7-21
环境
- hadoop2.9.1
- jdk1.8.0_171
- centOS7
- xshell
- windows10
概述
本文是在windows上的eclipse开发mapper reduce 使用yarn框架,并在虚拟机Hadoop集群上运行程序,大致过程是:先将编写好的代码文件打包好上传到虚拟机然后执行jar文件。
hadoop集群上运行hadoop自带程序示例(word count)
这里运行hadoop安装目录下\share\hadoop\mapreduce里面的“hadoop-mapreduce-examples-2.9.1”文件的wordcount
1.首先进入hadoop安装目录打开yarn集群,执行如下命令
- (首先确认配置好了yarn-site.xml和mapred-site.xml文件没配置的参考:yarn配置 - 点击打开)
1
2cd /home/hadoop/hadoop #进入到hadoop安装目录
./sbin/start-all.sh
2.打开集群之后先在集群创建输入文件夹以及上传输入文件,执行如下代码
- 首先在本地创建一个输入文件(这里是input.txt)
1
2touch input.txt //创建input.txt文件
ll //列出当前目录文件,查看是否创建成功
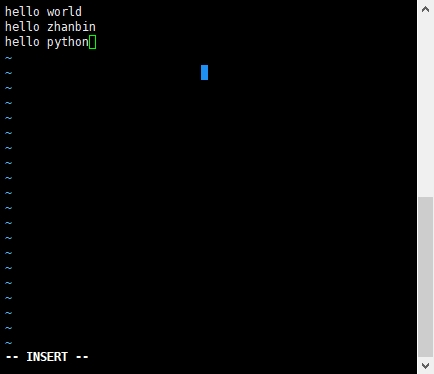
- 然后向input.txt添加自定义内容,如图是我所添加的内容
1
vi ./input.txt
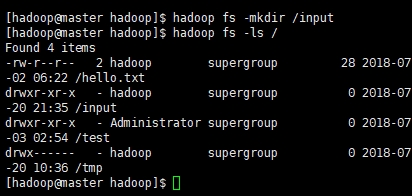
创建input文件夹作为存放输入文件的目录
1
hadoop dfs -mkdir /input
查看是否创建成功
1
hadoop fs -ls /
- 上传input文件到input目录
1
hadoop fs -put ./input.txt /input
3.打开之后找到mapreduce的自带示例代码文件
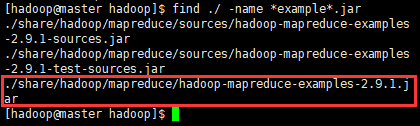
执行命令查看
1
2cd /home/hadoop/hadoop #进入到hadoop安装目录
find ./ -name *example*.jar找到hadoop-mapreduce-examples-x.x.x的文件,如图
然后执行如下命令(注意使用自己的路径,版本不同文件名会有所不同)
1
hadoop jar /share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /input/input.txt /output
没有报错则说明运行成功了
查看运行结果
1
2
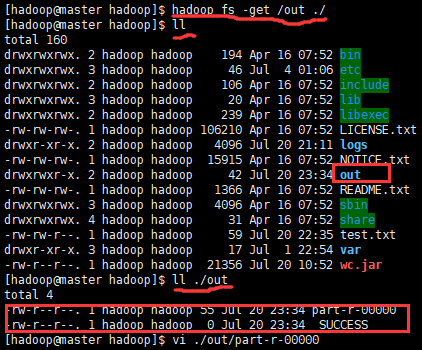
3hadoop fs -get /out ./ #将输出文件夹下载到本地目录
ll #这里是下载到当前目录,列出当前目录下文件查看是否下载成功
ll ./out #查看输出文件夹里面的文件
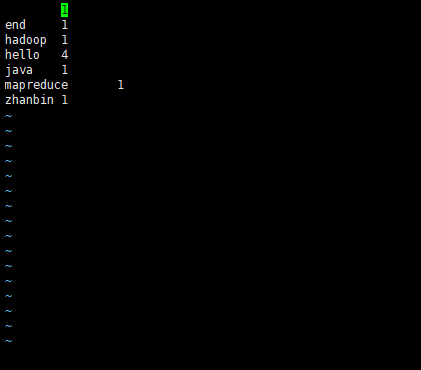
- 打开part-r-00000文件查看运行结果
1
vi ./out/part-r-00000
windows宿主机eclipse上传代码至hadoop集群运行
1.配置eclipse
- 配置eclipse参考链接:hadoop windows配置eclipse
2.代码
- 之前写了在windows本地运行wordcount的案例,这里参考之前的那篇文章,链接:第一个mapreduce程序 - 点击打开
3.运行
基于之前的代码修改下配置即可,将Test主类修改一下,加上hdfs集群的文件系统地址,下面的输入输出路径也换成相应的hdfs集群上的。如下图
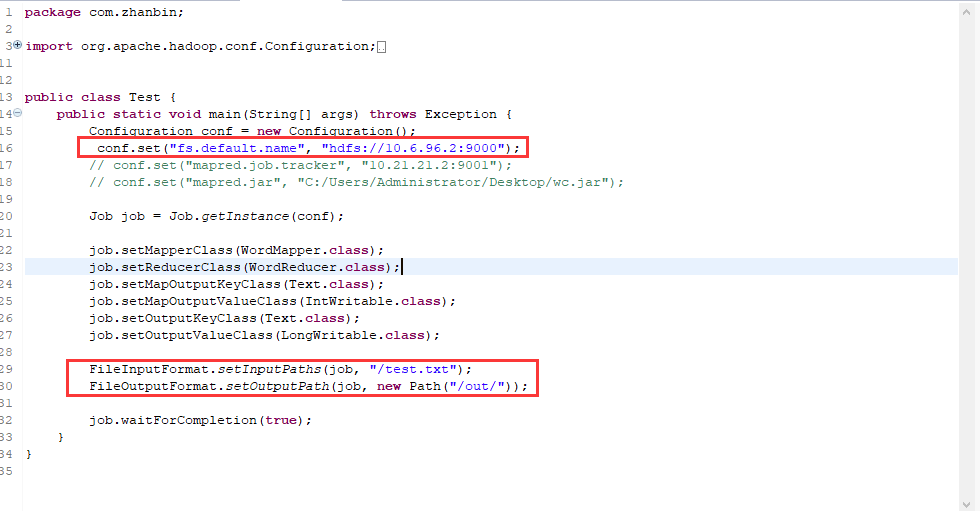
运行之前要先将刚刚的输出文件夹删除,或者在java代码设置成另一个文件夹。
run on hadoop
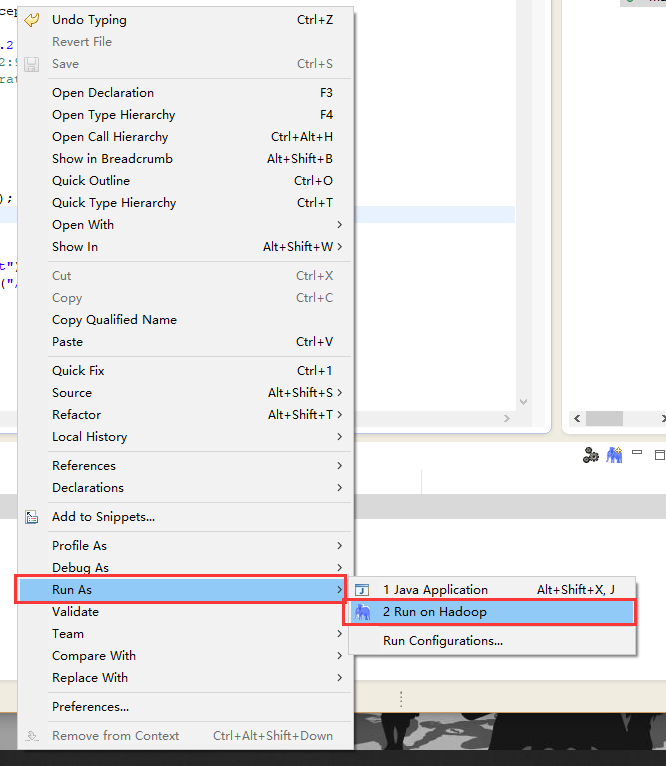
没有报错说明是运行成功了
查看运行结果
方法同上,这里就不再阐述了 查看运行结果
