
mapreduce原理及其执行过程
1.定义
- MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
- MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理
2.工作原理
map task
程序会根据InputFormat将输入文件分割成splits,每个split会作为一个map task的输入,每个map task会有一个内存缓冲区,输入数据经过map阶段处理后的中间结果会写入内存缓冲区,并且决定数据写入到哪个partitioner,当写入的数据到达内存缓冲区的的阀值(默认是0.8),会启动一个线程将内存中的数据溢写入磁盘,同时不影响map中间结果继续写入缓冲区。在溢写过程中,MapReduce框架会对key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件(最少有一个溢写文件),如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
reduce task
当所有的map task完成后,每个map task会形成一个最终文件,并且该文件按区划分。reduce任务启动之前,一个map task完成后,
就会启动线程来拉取map结果数据到相应的reduce task,不断地合并数据,为reduce的数据输入做准备,当所有的map tesk完成后,
数据也拉取合并完毕后,reduce task 启动,最终将输出输出结果存入HDFS上。
JobTracker,TaskTracker
JobTracker
- JobTracker协作作业的运行: 负责调度分配每一个子任务task运行于TaskTracker上,如果发现有失败的task就重新分配其任务到其他节点。
- 一般情况应该把JobTracker部署在单独的机器上。JobTracker与TaskTracker保持心跳
- JobTracker失败:
1:JobTracker失败在所有的失败中是最严重的一种;
2:hadoop没有处理jobtracker失败的机制。–它是一个单点故障。
3:在未来的新版本中可能可以运行多个JobTracker。
4:可以使用ZooKeeper来协作JobTracker。
TaskTracker
- TaskTracker运行作业划分后的任务
TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接
执行每一个任务,为了减少网络带宽TaskTracker最好运行在HDFS的DataNode上;
- TaskTracker失败:
1:一个TaskTracker由于崩溃或运行过于缓慢而失败,它会向JobTracker发送“心跳”。
2:如果有未完成的作业,JobTracker会重新把这些任务分配到其他的TaskTracker上面运行。
3:即使TaskTracker没有失败也可以被JobTracker列入黑名单。
MapReduce中Shuffle过程
Shuffle的过程:描述数据从map task输出到reduce task输入的这段过程。
我们对Shuffle过程的期望是:
- 完整地从map task端拉取数据到reduce task端
- 跨界点拉取数据时,尽量减少对带宽的不必要消耗
- 减小磁盘IO对task执行的影响
先看map端: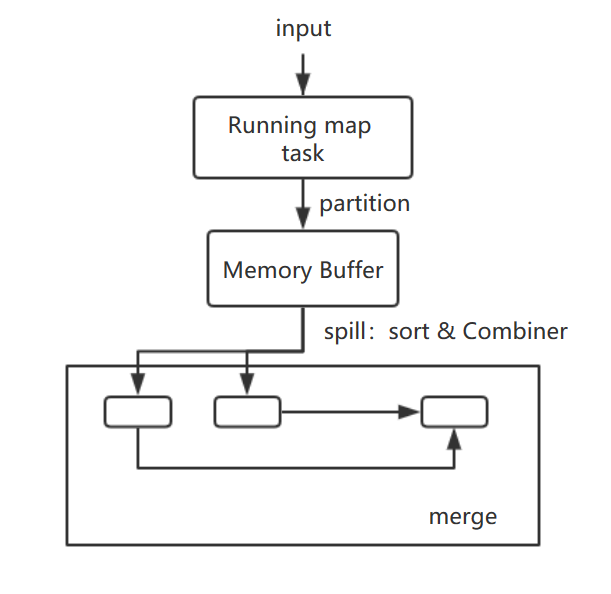
split被送入map task后,程序库决定数据结果数据属于哪个partitioner,写入到内存缓冲区,到达阀值,开启溢写过程,进行key排序,
如果有combiner步骤,则会对相同的key做归并处理,最终多个溢写文件合并为一个文件。
再看reduce端: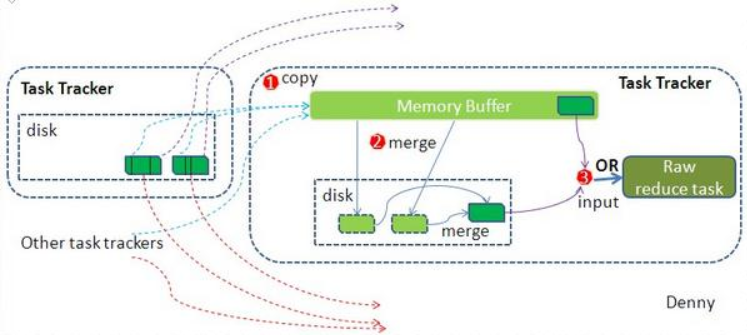
多个map task形成的最终文件的对应partitioner会被对应的reduce task拉取至内存缓冲区,对可能形成多个溢写文件合并,最终
作为resuce task的数据输入 。
3.Word Count举例
Word Count过程示例
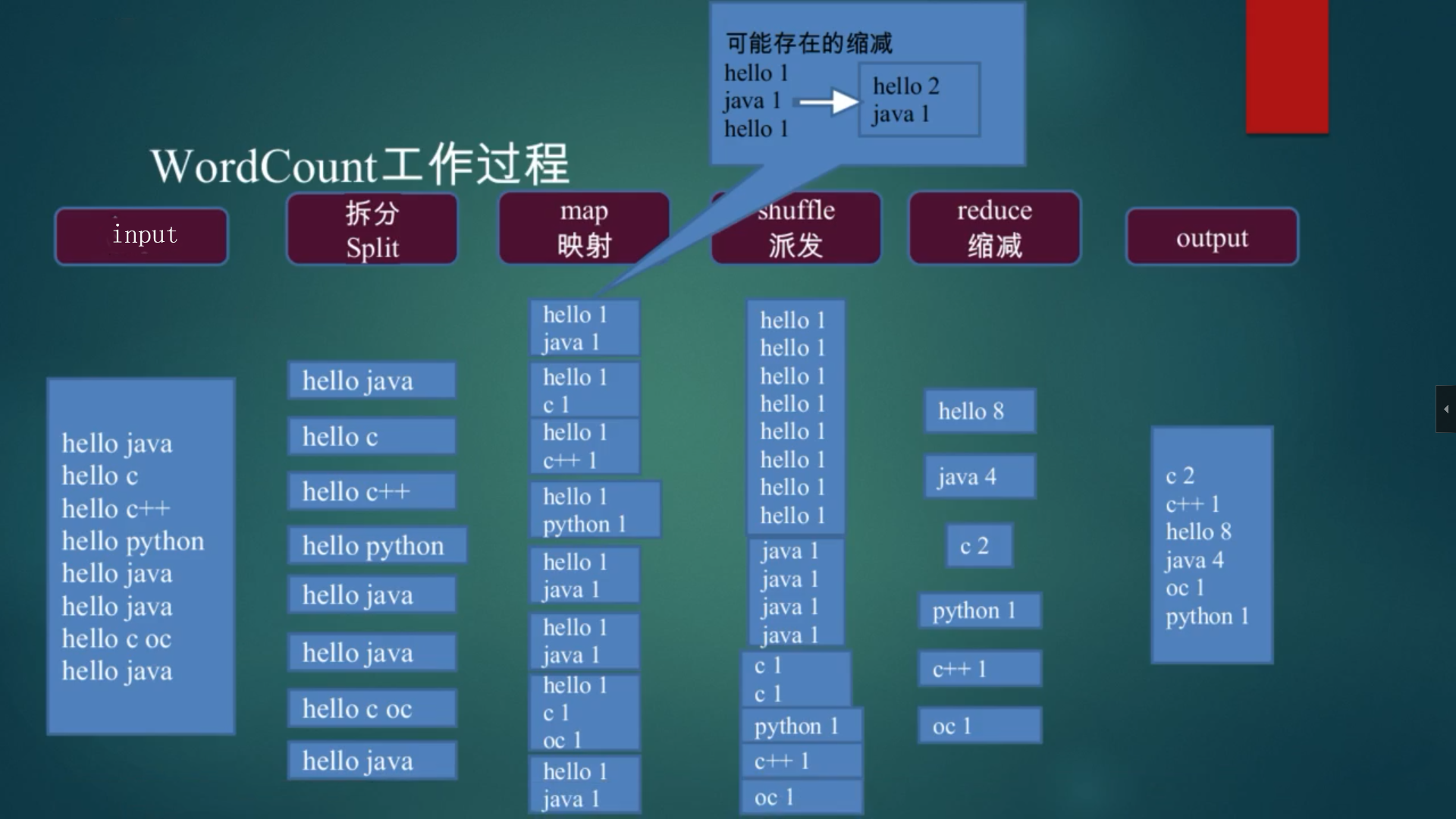
MapReduce编程主要组件
InputFormat类:分割成多个splits和每行怎么解析。
Mapper类:对输入的每对<key,value>生成中间结果。
Combiner类:在map端,对相同的key进行合并。
Partitioner类:在shuffle过程中,将按照key值将中间结果分为R份,每一份都由一个reduce去完成。
Reducer类:对所有的map中间结果,进行合并。
OutputFormat类:负责输出结果格式。
Word Count编程实现
参考链接:Word Count实例
