
一种基于哈希的字符串匹配(论文综述)
论文来源:IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 30, NO. 1, JANUARY 2018
论文原文:String Similarity Search: A Hash-Based Approach
密码:5bp0
摘要
字符串相似性搜索是一种基本查询,它已经杯广泛应用于数据库,数据仓库和数据挖掘所需的DNA测序,自动完成容错查询和数据清理。在本文中,研究了基于编辑距离的字符串相似性搜索,这是由许多数据管理系统支持的,大多数现有的工作都采用过滤和验证方法。
这里提出了两种基于哈希标签的字符串匹配技术。这两种标签称为OX和XX标签,通过对比哈希标签来判定两个字符串是否相似,这个算法实现了高效率,并且使索引大小和索引构建时间比实验中现有的方法同时缩短了一个数量级。
Index Terms—Similarity search, hash, edit distance
1.编辑距离
1.1 概述
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
1.2 编辑距离计算
下图展示了两个字符串之间的编辑距离计算过程,编辑距离是取最小的那个,下面看到两组的字符串都是相同的但是使用的操作不一样,计算出来的编辑距离不一样。编辑距离是不停地用插入、删除、替换操作将两个字符串变成一样,遍历完所有可能的操作之后取最小的一个编辑距离。
1.3 计算机计算编辑距离
上面说到我们尝试所有的将两个字符串变成相同夫人操作,取最小的编辑距离。而计算机是使用矩阵来计算编辑距离。
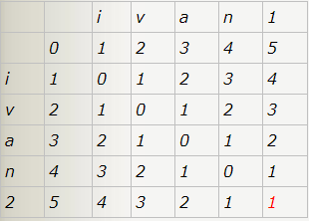
计算机计算编辑距离的常用方法是填充两个字符串的距离矩阵,右下角的最后一个元素的值就是这两个字符串的编辑距离。
开始我们初始化一个矩阵,假设有两个字符串S_1和S_2长度分别为m和n,先构建一个 n+1 * m+1 初始矩阵。这里比较“ivan1”和“ivan2”两个字符串。
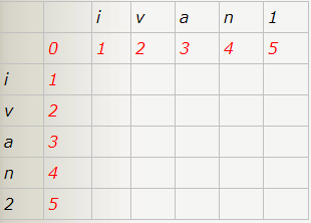
扫描两字符串(n*m级的),如果:str1 [i]== str2[j],用temp记录它,为0。否则temp记为1。
然后在矩阵d[i,j]赋于d[i-1,j]+1 、d[i,j-1]+1、d[i-1,j-1]+temp三者的最小值。
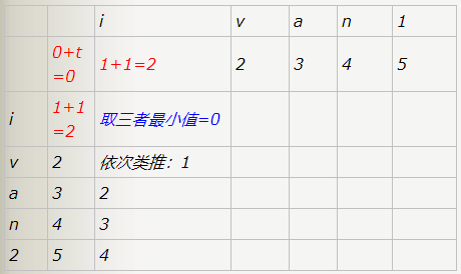
最后填充完距离矩阵之后矩阵的最后一个元素的值即是这两个字符串的编辑距离。
2. 基于哈希标签的字符串匹配方法
2.1 概述
基于哈希标签的字符串匹配方法是这篇文章主要介绍的一种新技术,传统的基于编辑距离的字符串相似性搜索需要填充距离矩阵在字符串比较长的时候会大大增加计算开销,对此这篇文章提出了一种基于散列的匹配方法。这个方法通过对单个字符赋初始值,然后计算q-gram字符串序列的哈希值,再根据字符串当中序列的出现与否给哈希标签赋值。
我们设定哈希标签长度L=20,s = “effcionsy” 、t =“efficiency” ,τ=2,q=2, 则Qs = {$e, ef, ff, fc, ci, io, on, ns, sy, y$} Qt = {$e, ef, ff, fi, ic, ci, ie, en, nc, cy y$}。
这里有两种哈希标签XX和XO,假如ef的哈希值为14(假设没有哈希冲突),ef出现了一次,则哈希标签对应第14位则标为1,以此类推,直到遍历完q-gram字符序列。
哈希标签初始化(共20位):
XX:00000000000000000000
XO:00000000000000000000
2.2用到的函数

2.3计算字符串q-gram子串哈希值

2.4 哈希标签的计算
哈希标签的计算过程:假如出现了“ff”字串,而ff的哈希值是14,则对哈希标签的第14位的值进行更新操作,旧的标签值和1进行“异或”(XX)或者“或”(OX)操作。如下图,下图的H[i]表示哈希标签的第i位。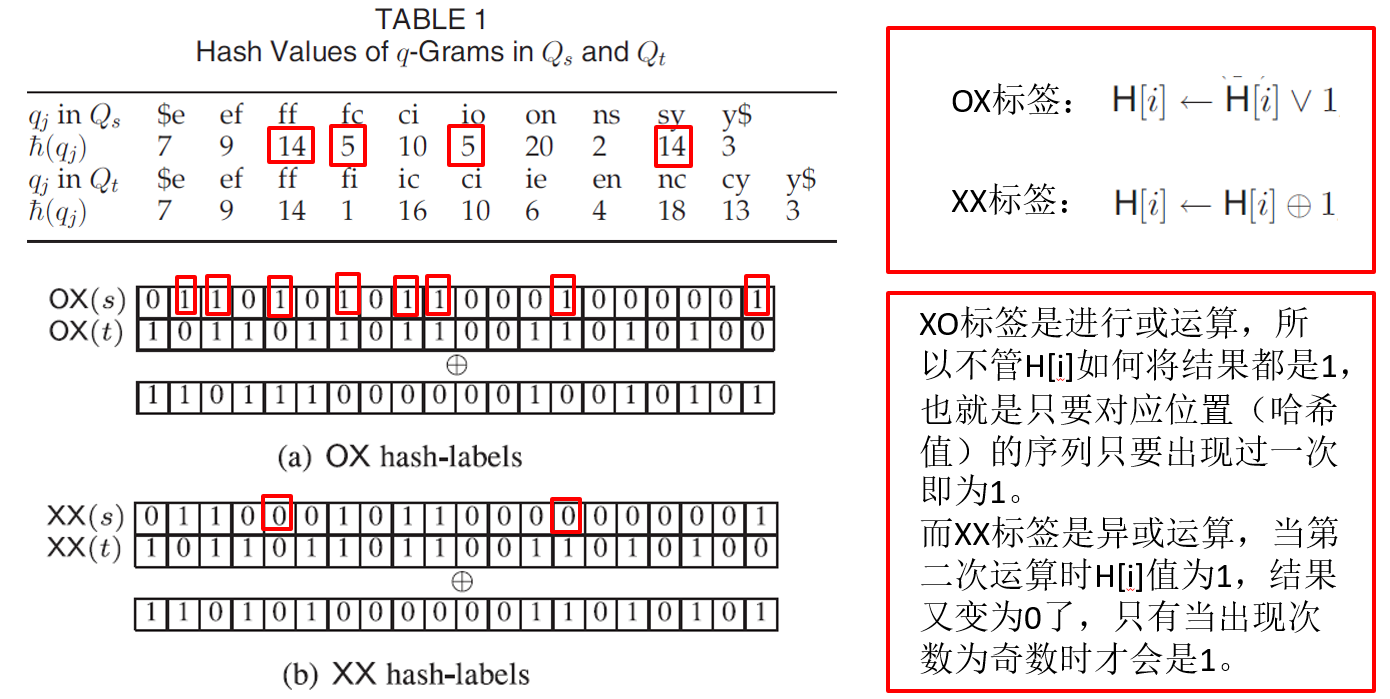
计算出哈希标签之后计算标签里面的1的个数,然后与给定的阈值t作比较,如果大于阈值则两个字符串不被考虑为相似。
