Windows上第一个mapreduce程序
作者:Zhan-bin
日期:2018-07-07
MapReduce原理及其执行过程
- 这里实在windows上开发执行mapreduce程序,如果要放到hdfs集群,将地址改成集群地址即可。
- Map Reduce原理参考参考链接:MapReduce原理及其执行过程
导包
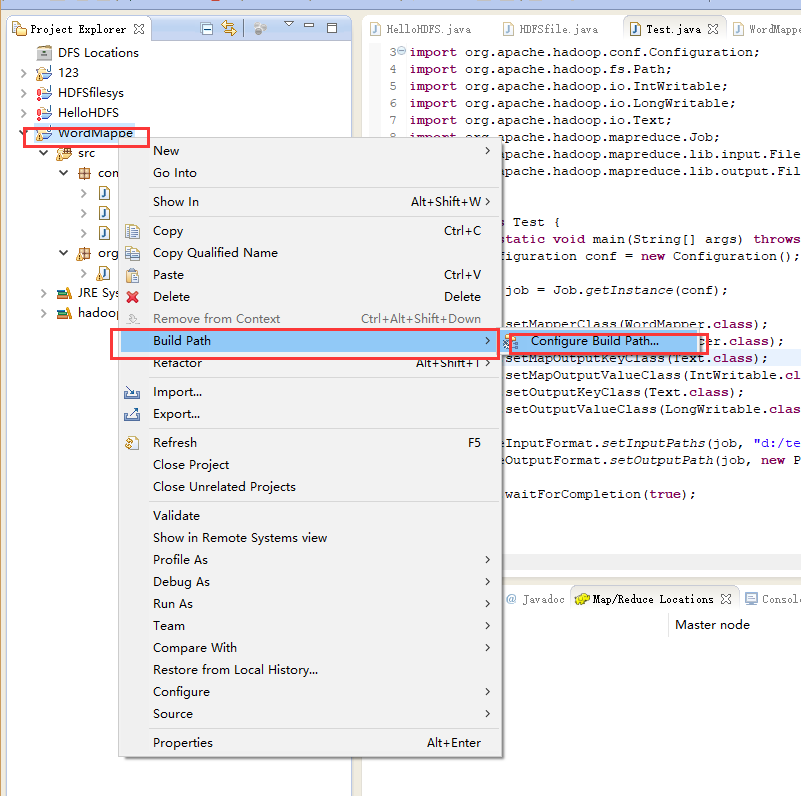
- 添加一个名为hadoop的Library图片里面我这里时已经添加好了的。
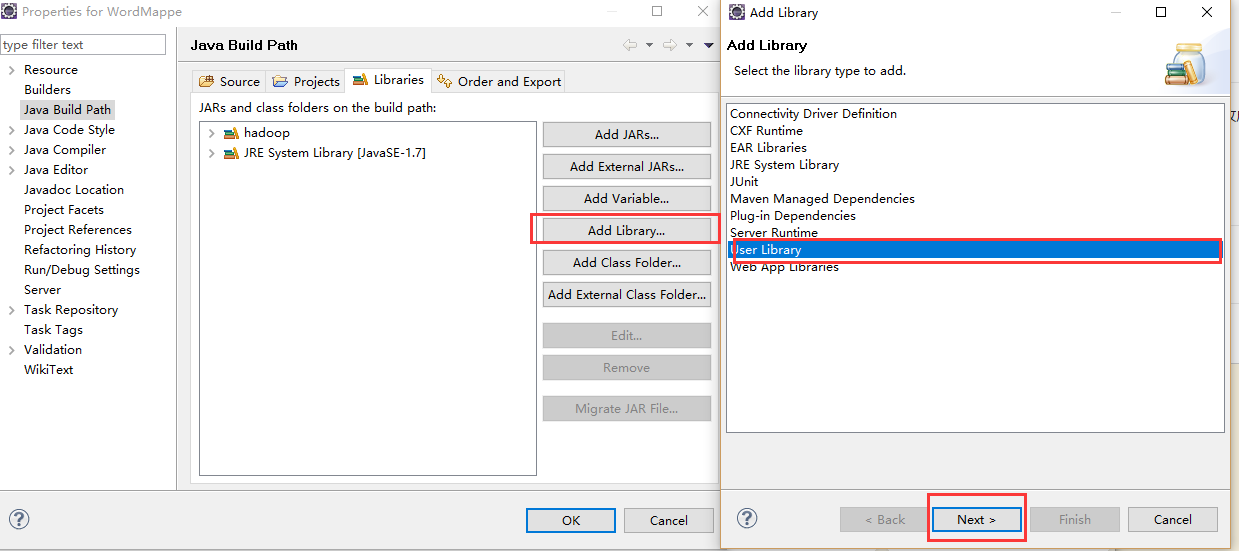
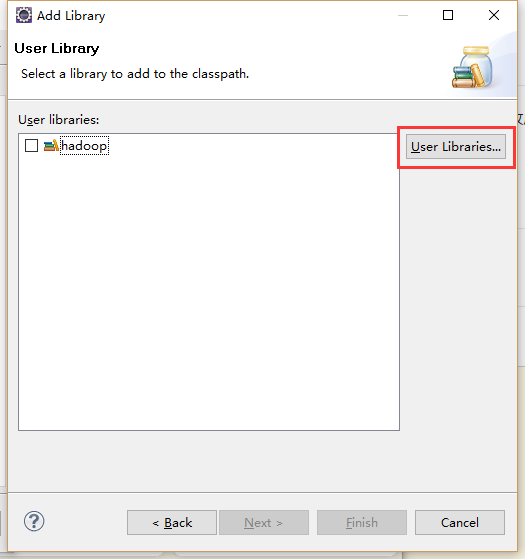
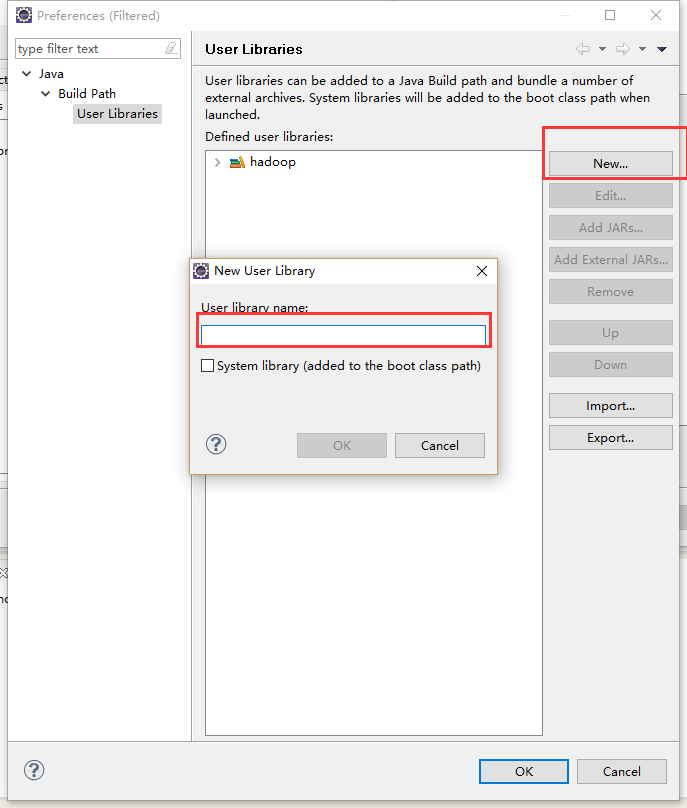
新建完然后就添加jar包到自己的新建目录下面
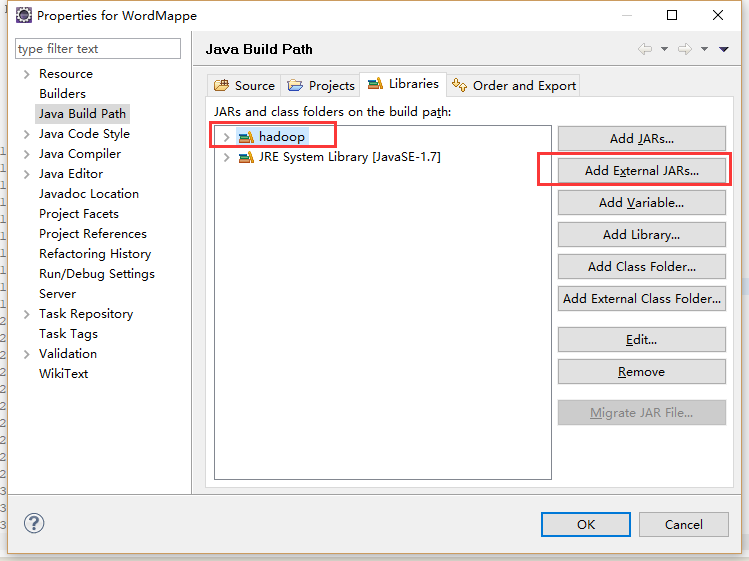
进入Hadoop安装目录后找到share文件夹进入hadoop文件夹
- common文件夹里面需要导入的包: hadoop-common-2.9.1.jar和lib里面的所有包
- hdfs文件夹里面需要导入的包:hadoop-hdfs-2.9.1.jar,hadoop-hdfs-client-2.9.1.jar
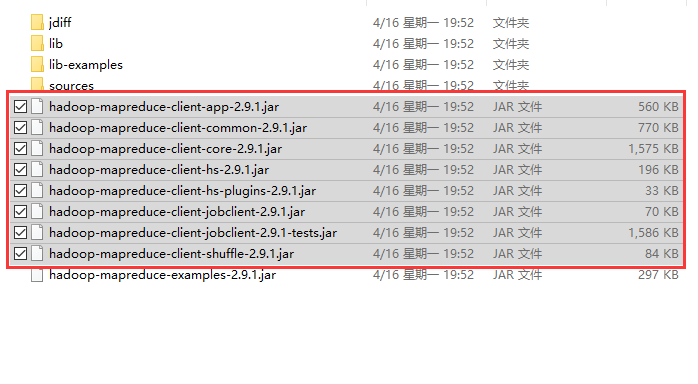
mapreduce文件夹里面需要导入的包:下图选中的和lib里面的所有包
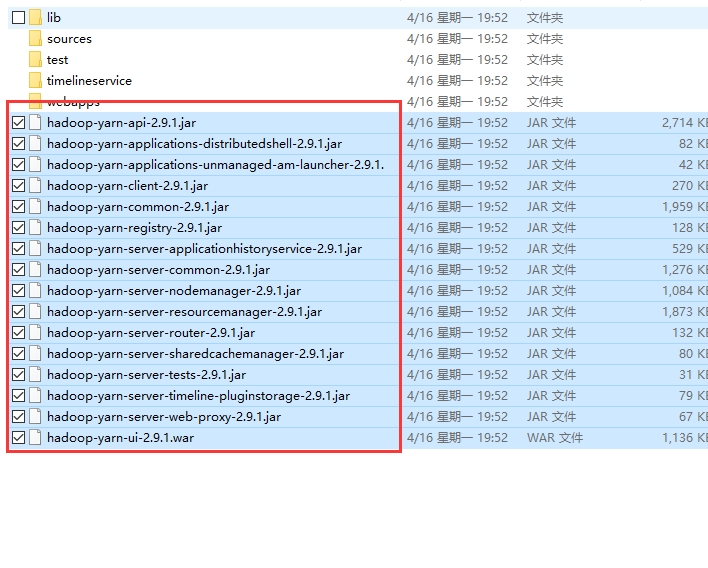
yarn文件夹里面需要导入的包:下图选中的和lib里面的所有包
这样一来我们就不用每次都要到文件夹导包了,直接选中刚刚新建的hadoop就可以了。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| package com.zhanbin;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordMapper extends Mapper<LongWritable,Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| package com.zhanbin;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordReducer extends Reducer<Text, IntWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long count = 0;
for(IntWritable v : values) {
count += v.get();
}
context.write(key, new LongWritable(count));
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| package com.zhanbin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Test {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, "d:/test.txt");
FileOutputFormat.setOutputPath(job, new Path("d:/out/"));
job.waitForCompletion(true);
}
}
|
- 执行Test.java测试,这里是将我电脑本地的test.txt作为输入,将词频结果输出到本地电脑的目录。
执行时可能会出现“org.apache .hadoop.io.nativeio.NativeIO$Windows.access0 (Ljava/lang/String;I)Z” 的错误。
出现这个错误可以参考:运行Map Reduce出错

