
5种常用的推荐系统算法
概述
常用的推荐系统算法有五种,每一种都有其优点,不同场景下每一种算法效果会不一样。(下面是常用的推荐系统算法)
- 1.基于内容的推荐
- 2.协同过滤推荐
- 3.基于关联规则的推荐
- 4.基于知识的推荐
- 5.混合推荐
1.基于内容的推荐
基于内容的推荐系统会挖掘用户曾经喜欢的物品,从而去推荐类似的物品。本质上就是利用用户已知偏好,兴趣等特征和物品的特征相匹配,以此为用户推荐新的感兴趣的商品,这种算法主要是要提取推荐对象的特征。
优点:
- 简单、有效、结果易于理解且算法比较成熟
- 只需要从当前用户构建兴趣模型、不需要像CF一样找近邻
- 在冷启动情况下都适用
- 没有稀疏问题
缺点:
- 依赖于提取出来的特征,提取特征的能力会限制算法的效果、可分析内容有限
- 新颖性不如其他算法,无法发现令人惊喜的推荐
- 算法需要有足够和真实的用户数据
2.协同过滤算法
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。协同过滤推荐算法分为两类,分别是基于邻域的模型算法、隐语义分析以及基于图的算法
引用:https://blog.csdn.net/yimingsilence/article/details/54934302?utm_source=copy
(1)基于领域的模型
基于邻域的模型分为两种分别为基于用户和基于物品的协同过滤
基于用户的协同过滤算法
基于用户的协同过滤算法是推荐系统中最古老的算法。可以不夸张地说,这个算法的诞生标志了推荐系统的诞生。该算法在1992年被提出,并应用于邮件过滤系统,1994年被GroupLens用于新闻过滤。在此之后直到2000年,该算法都是推荐系统领域最著名的算法。
下图是基于Facebook好友的个性化推荐列表
基于用户的协同过滤算法主要包括两个步骤。
- (1)找到和目标用户兴趣相似的用户集合。
- (2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤(1)的关键就是计算两个用户的兴趣相似度。这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。那么,我们可以通过如下的Jaccard公式简单地计算u和v的兴趣相似度: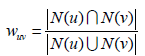
或者通过余弦相似度计算: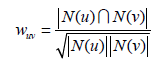
下面以图中的用户行为记录为例,举例说明UserCF计算用户兴趣相似度的例子。在该
例中,用户A对物品{a, b, d}有过行为,用户B对物品{a, c}有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度为: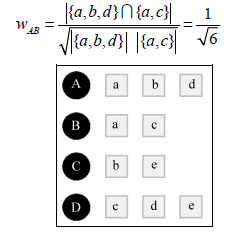
同理,我们可以计算出用户A和用户C、D的相似度: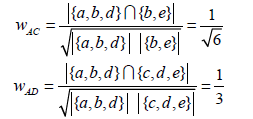
基于物品的协同过滤算法
基于物品的协同过滤(item-based collaborative filtering)算法是目前业界应用最多的算法。无论是亚马逊网,还是Netflix、Hulu、YouTube,其推荐算法的基础都是该算法。
下图展示了亚马逊在iPhone商品界面上提供的与iPhone相关的商品
下图为Hulu的个性化视屏推荐界面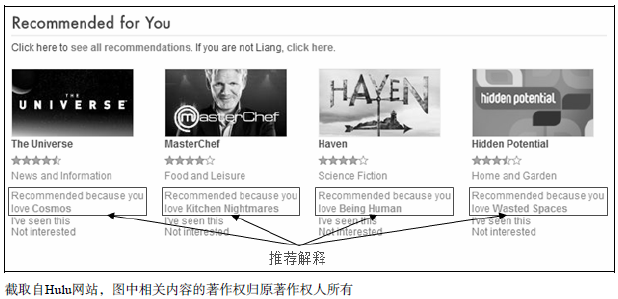
基于物品的协同过滤算法主要分为两步:
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为给用户生成推荐列表。
我们可以用下面的公式定义物品的相似度: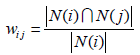
这里,分母|N(i)|是喜欢物品i的用户数,而分子是同时喜欢物品i和物品j的用户数。因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。
上述公式虽然看起来很有道理,但是却存在一个问题。如果物品j很热门,很多人都喜欢,那么Wij就会很大,接近1。因此,该公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,可以用下面的公式: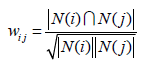
这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。从上面的定义可以看到,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。这里面蕴涵着一个假设,就是每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它们就可能属于同一个领域,因而有很大的相似度。
(2)隐语义模型算法
LFM(latent factor model)隐语义模型最早在文本挖掘领域被提出,用于找到文本的隐含语义。相关的名词有LSI、pLSA、LDA和Topic Model。它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品。,其中和该技术相关且耳熟能详的名词有pLSA、LDA、隐含类别模型(latent class model)、隐含主题模型(latent topic model)、矩阵分解(matrixfactorization)。这些技术和方法在本质上是相通的,其中很多方法都可以用于个性化推荐系统。
例如:每本书出版时,编辑都会给书一个分类。为了给图书分类,出版界普遍遵循中国图书分类法。但是,即使有很系统的分类体系,编辑给出的分类仍然具有以下缺点。
- 编辑的意见不能代表各种用户的意见。比如,对于《具体数学》应该属于什么分类,有人认为应该属于数学,有些人认为应该属于计算机。从内容看,这本书是关于数学的,但从用户看,这本书的读大部分是做计算机出身的。编辑的分类大部分是从书的内容出发,而不是从书的读者群出发。
- 编辑很难控制分类的粒度。我们知道分类是有不同粒度的,《数据挖掘导论》在粗粒度的分类中可能属于计算机技术,但在细粒度的分类中可能属于数据挖掘。对于不同的用户,我们可能需要不同的粒度。比如对于一位初学者,我们粗粒度地给他做推荐就可以了,而对于一名资深研究人员,我们就需要深入到他的很细分的领域给他做个性化推荐。
- 编辑很难给一个物品多个分类。有的书不仅属于一个类,而是可能属于很多的类。
- 编辑很难给出多维度的分类。我们知道,分类是可以有很多维度的,比如按照作者分类、按照译者分类、按照出版社分类。比如不同的用户看《具体数学》原因可能不同,有些人是因为它是数学方面的书所以才看的,而有些人是因为它是大师Knuth的著作所以才去看,因此在不同人的眼中这本书属于不同的分类。
- 编辑很难决定一个物品在某一个分类中的权重。比如编辑可以很容易地决定《数据挖掘导论》属于数据挖掘类图书,但这本书在这类书中的定位是什么样的,编辑就很难给出一个准确的数字来表示。
下图是两个用户的读书列表
(3)基于图的模型
基于图的模型(graph-based model)是推荐系统中的重要内容。其实,很多研究人员把基于邻域的模型也称为基于图的模型,因为可以把基于邻域的模型看做基于图的模型的简单形式。
在研究基于图的模型之前,首先需要将用户行为数据表示成图的形式。本章讨论的用户行为数据是由一系列二元组组成的,其中每个二元组(u, i)表示用户u对物品i产生过行为。这种数据集很容易用一个二分图表示。
令G(V,E)表示用户物品二分图,其中V=VU ⋃ VI由用户顶点集合 VU 和物品顶点集合VI组成。对于数据集中每一个二元组(u, i),图中都有一套对应的边e(vu,vi) ,其中vu∈VU是用户u对应的顶点,vi∈VI是物品i对应的顶点。
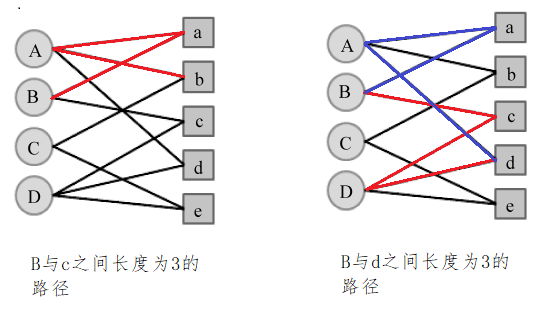
下图是一个简单的用户物品二分图模型,其中圆形节点代表用户,方形节点代表物品,圆形节点和方形节点之间的边代表用户对物品的行为。比如图中用户节点A和物品节点a、b、d相连,说明用户A对物品a、b、d产生过行为。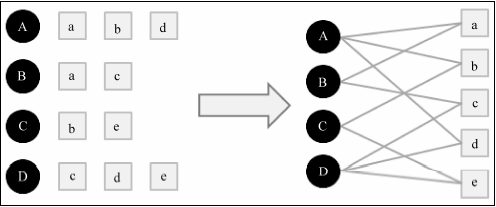
举一个简单的例子,下图中用户B和物品b、d没有边直接相连,但是用户B和物品b有一条长度为3的路径相连,用户B和物品d有两条长度为3的路径相连。那么顶点B与d之间的相关性要高于顶点B与b,因此物品d在B的推荐列表中应该排在b之前。
下图为一种基于图的推荐模型的应用:豆瓣读书的个性化推荐应用“豆瓣猜”的界面
3.基于关联规则的推荐
关联规则用来发现数据间潜在的关联,最典型的就是电商的购物车分析。
如下图所示:下图表格里面的是用户购买的物品清单。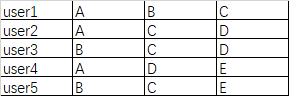
然后我们将这个表格转换成用0,1表示的二维表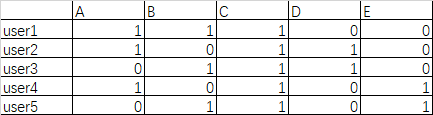
在关联规则中有三个重要的树术语,分别是支持度(Support)、可信度(Confidence)和作用度(Lift)。支持度是一件商品在所有的购物车里面出现的频率。如果我们希望是两件商品的关联,那么支持度就是这两件商品同时出现的频率。支持度是用于挖掘关系的普遍性。可信度是指两件商品中当第一件出现时,第二件商品出现的频率。
- 支持度:
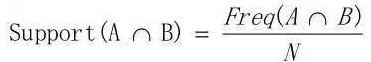
可信度:
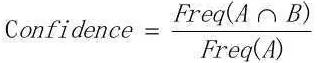
作用度:
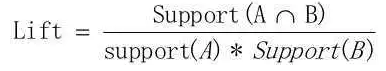
举个简单的例子:可乐和薯片的关联规则的支持度是20%,购买可乐的支持度是30%,购买薯片的支持度是50%,则提升度是1.33>1, A-B规则对于商品有提升效果。
4.基于知识的推荐
基于知识的推荐系统大致工作流程是用户指定需求,然后系统设法给出解决方案。如果找不到解决方案,用户需要修改需求(再次说明基于知识推荐系统的交互性很强)。此外,系统还要给出推荐物品的解释。基于知识推荐系统主要包括两种类型,基于约束推荐和基于实例推荐,它们的区别在于如何使用所提供的知识:基于实例的推荐系统着重于根据不同的相似度衡量方法检索出相似的物品(也就是根据相似度衡量标准检索哪些与特定用户需求相似的物品),基于约束的推荐系统以来明确定义的推荐规则集合(在符合推荐规则的所有物品集合中搜索得出要推荐的物品集合)。
协同过滤和基于内容的推荐在很多情况下无法发挥作用,例如:1)有些物品我们并不会频繁购买,比如房屋,纯粹的协同过滤系统会由于评分数据很少而效果不好;2)时间跨度因素的作用很重要,多年前对物品的评分对基于内容推荐来说就不太合适,因为用户偏好会随着生活方式或家庭情况的变化而改变;3)在一些复杂的产品领域,用户希望明确定义他们的需求,例如“汽车的最高价是x,颜色是黑色”,这种需求的形式化处理并不是纯粹协同过滤和基于内容推荐所擅长的(关于这个第三条,在以前对于推荐系统的概念中,没有把这种明确需求的形式认为是推荐系统的一种,而是认为这是一种检索系统,后面的讨论中会在做说明)。
基于知识的推荐系统可以解决上述问题:1)由于不需要评分数据就能推荐,也就不存在启动问题;2)推荐结果不依赖单个用户评分,要么是以用户需求与产品之间的相似度的形式,要么是根据明确的推荐规则;3)关于推荐系统是什么,传统解释一般强调信息过滤这一方面,即过滤出某个用户可能感兴趣的商品,而基于知识的推荐交互性很强,使得推荐系统不在仅仅被看做一种推荐系统,而是“以一种个性化方法引导用户在大量潜在候选项中找到感兴趣或有用物品,或者将这些物品作为输出结果”的系统。
5.混合推荐
混合推荐即将上面的4种算法组合应用,充分利用各个算法的优点解决现实的问题。
