
全分布配置
作者:Zhan-bin
日期:2018-6-28
1.搭建环境
这里的配置为 VMware+CentOS7+hadoop2.9.1
这里我下载的镜像是 CentOS-7-x86_64-Minimal-1804.iso
(这里使用的是hadoop2.9.1 尽量下载stable文件夹里面的稳定版本。下载”stable”下的hadoop-2.x.y.tar.gz这个格式的文件)
- 也可以直接用和我一样的,
本文使用的jdk下载地址
本文使用的hadoop下载地址
2.虚拟机安装CentOS及创建hadoop用户
- 打开VMware 选择创建新的虚拟机-典型-安装程序镜像文件
- 这里选择刚刚下载好的镜像文件点击下一步
- 这里选择系统的安装目录
设置完之后直接开启虚拟机,等待安装系统。
这里需要设置好root用户的密码以及创建一个新用户,名为 hadoop 。

- 安装系统的时候忘记创建了,就输入如下命令创建:
1
2useradd hadoop #创建hadoop用户
passwd hadoop #设置密码
3.配置系统网络
3.1 虚拟机网络连接配置
开机之后,先设置网络,在下图框住的位置点击鼠标右键选择设置将网络设置选择NAT模式,点击确定之后回到刚刚界面还是右键刚刚那个图标连接网络。
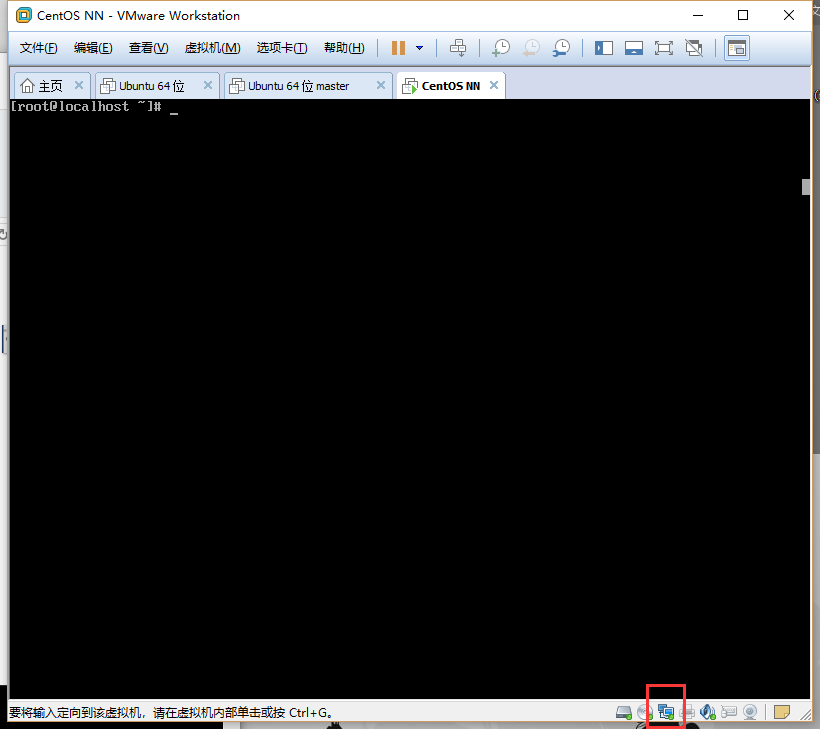
- 输入ifconfig,出现“fconfig command not found”
- CentOS7是默认没有安装net-tools的,所以这里安装一下,如果不确定有没有就输入ifconfig,会提示“fconfig command not found”。
确认sbin目录是否存在。
1
cd /sbin
确认ifconfig命令是否未安装
在sbin目录下输入ls,如果没有ifconfig就执行下面命令安装。1
sudo yum install net-tools
这个命令是从网上安装的,如果虚拟机不能连接外网,就先执行完下面网络配置步骤再进行安装。
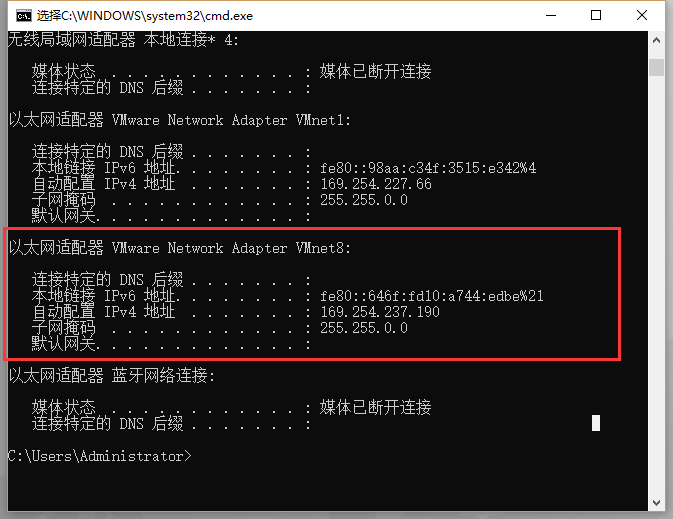
- 回到自己的电脑 win+r 打开cmd输入ipconfig查看VMware Network Adapter VMnet8的IP地址
- 配置完之后,用root用户登陆主机,输入命令
1 |
|
- 然后再输入下面命令打开ifcfg-ens33的文件:
1 |
|
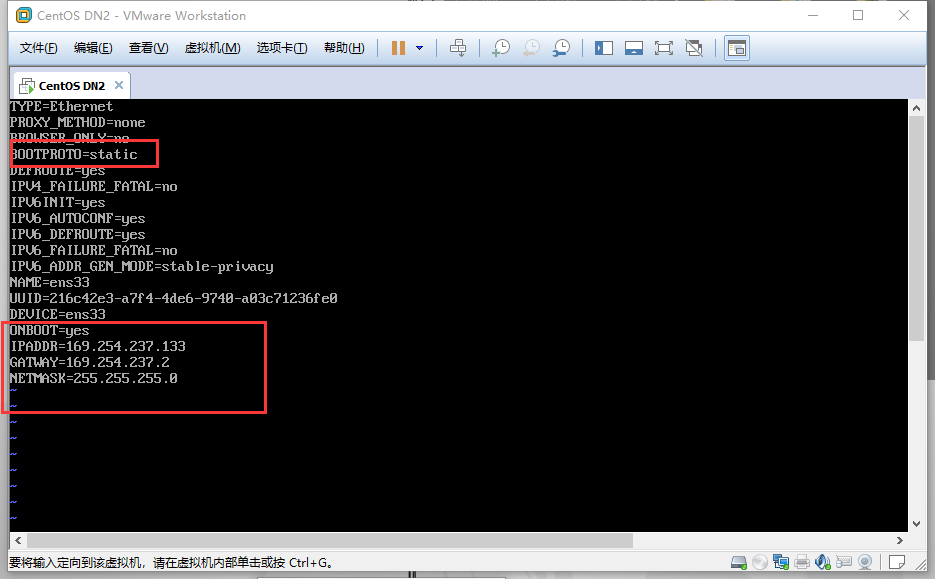
- 进入文件编辑界面,将其中的onboot=no,改成onboot=yes,添加几行代码(如下图):
IPADDR 填写与刚刚查看的自己电脑VMware Network Adapter VMnet8的ipv4同一个子网的一个IP地址比如我这里是169.254.237.190,就填写169.254.237.xxx XXX填写0-255之间的任何一个数即可(不要和主机、网关、其他虚拟机的一样)
GATWAY直接填VMware Network Adapter VMnet8的网关
NETMASK一般填255.255.255.0
- 改完之后,保存退出,输入重启网络的命令:
1 |
|
- 再ping百度测试是否连接上网络:
1 |
|
如果出现问题,也可以设置桥接,静态IP的形式:虚拟机配置桥接
3.2 虚拟机域名配置
当3台虚拟机均安装完成后,需要进行的是修改机器名、添加域名映照、关闭防火墙
3.2.1 修改机器名
- 命令行输入cd回车回到根目录下,执行下面命令打开network文件,在其中添加“HOSTNAME=cMaster”,然后重启当前虚拟机,再查看机器名就是cMaster了。:
1 |
|
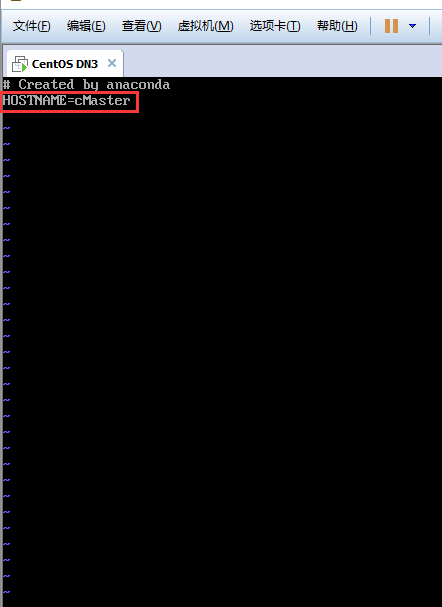
-然后重启机器
1 |
|
- 查看主机名:
1 |
|

(如果重启以后机器名不是cMaster,可使用命令hostnamectl set-hostname cMaster修改机器名)
3.2.2 添加域名映射
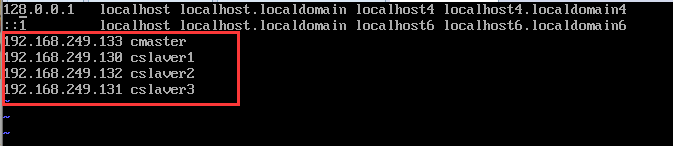
- 使用ifconfig命令分别查看3台虚拟机的IP地址。然后将3个ip地址都添加到各自的/etc/hosts文件中,3台主机的ip配置以下图。
1 |
|
- 按如下格式添加主机名和相应ip地址的映射
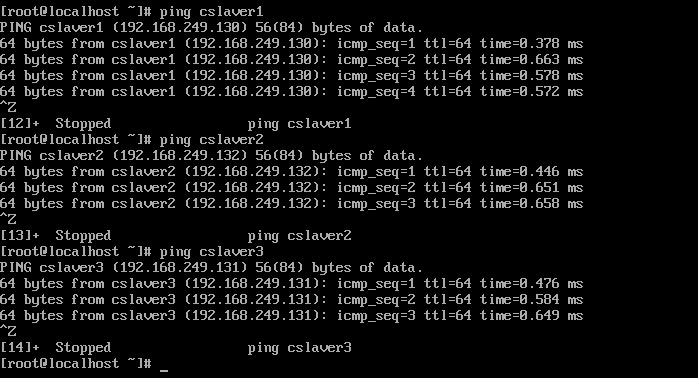
- 再ping下各个主机试试可不可以ping通(如下图所示)。建议先ping下这几台虚拟机的ip看可不可以ping通之后再ping各自的主机名。
3.2.3 关闭防火墙
- 在root权限下履行以下两条指令,关闭防火墙并禁止其开机启动。
1 |
|
3.2.4 使用xshell将文件上传到linux虚拟机上
- 没用过xshell的话可以参考: xshell文件上传-点击打开
4.安装JDK
4.1将文件放到安装目录下面
- (1)先建立jdk安装目录,这里我是安装在 /home/hadoop/java 下。
1 |
|
- (2)转到jdk文件所在文件夹,将刚刚从自己电脑上传的JDK复制到java安装路径中,执行命令:
1 |
|
- (3)解压
1 |
|
4.2 配置环境变量
- (1)先执行cd 切换到根目录下再执行 sudo vi /etc/profile ming ,然后将一段一段代码插入到文件的末尾 命令如下:
1 |
|
- 将下面代码插入到文件末尾
1 |
|
- (2)执行update-alternatives
1 |
|
1 |
|
- (3)重新加载 /etc/profile
1 |
|
- (4)测试(执行如下命令测试是否安装成功)
1 |
|

5. 安装Hadoop
5.2 复制并解压文件
这里使用的是hadoop2.9.1 尽量下载stable文件夹里面的稳定版本。下载”stable”下的hadoop-2.x.y.tar.gz这个格式的文件
- (1)将刚刚上传到linux虚拟机的Hadoop文件复制到Hadoop安装路径,这里我的安装路径是 /home/hadoop/hadoop ,复制过去之后解压并将文件夹名改为hadoop(这里我就没有创建hadoop文件夹了,直接解压到local,将解压后的文件夹重命名为hadoop)。
1 |
|
- (2)解压之后直接测试有没有装成功
1 |
|
如果出现 JAVA_HOME not found 之类的提示就将hadoop里的JAVA_HOME设成绝对地址:hadoop找不到java-点击打开)

5.1 配置hadoop环境变量
- (1)打开系统文件(添加如下图框框内的内容):
1 |
|
- (1)在末尾加上hadoop安装路径(这里我的hadoop安装路径是/usr/local/hadoop,如果你的不是这个目录,就把后面的/usr/local/hadoop改为你自己的安装目录)
1 |
|
- (2)在PATH的后面加上下面内容:
1 |
|
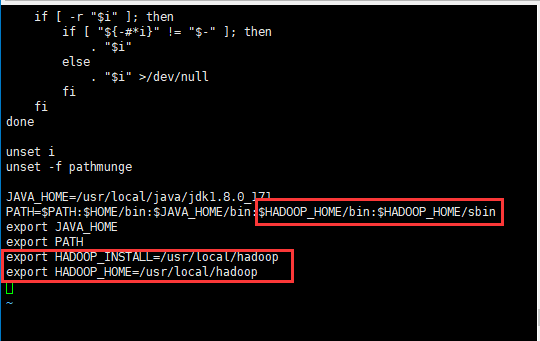
- (3)重新加载下profile
1 |
|
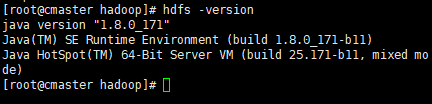
- (4)输入“hdfs -version”测试下有没有安装成功
5.2 更改hadoop配置文件
Hadoop的配置文件都是放在安装目录下的“/etc/hadoop”里面
5.2.1cmaster主机配置文件设置
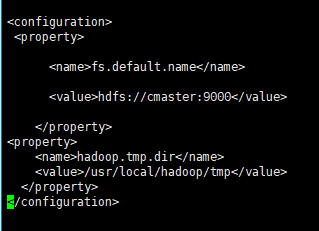
- (1)更改core-site.xml。(在
标签里面添加如下代码)
命令:
1 |
|
在最后
1 |
|
(2) 修改hadoop安装目录下的/etc/hadoop里面的slaves文件(这个文件是记录master主机管理的所有主机,将自己的datanode添加进去即可)。
先进入到hadoop安装目录
1 |
|
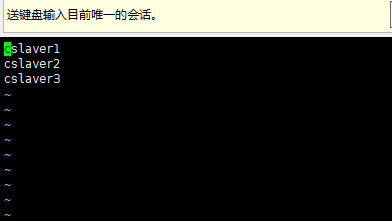
- 打开slaves文件。
1 |
|
- 将文件覆盖成如下内容(我的三台数据节点分别为cslaver1;cslaver2;cslaver3,不一定要和我相同,名字要和前面的hosts文件的映射对应上,根据自己的数据节点的主机名修改):
1 |
|
5.2.2更改cslaver1和cslaver2的配置文件
- 数据节点只需修改core-site.xml文件,文件添加内容同上。
6. 安装ssh免密登陆
6.1设置名称节点(cmaster)
- (1)生成密钥对,执行如下命令:
1 | cd ~/.ssh/ |
- 然后有提示就按【Enter】键,就会依照默许的选项将生成的秘钥对保存在.ssh/id_rsa文件中。
- (2)进入.ssh目录履行以下命令
1 |
|
- (3)配置SSH
1 |
|
将RSAAuthentication yes//前面的#去掉
PubkeyAutentication yes//前面的#去掉
AuthorizedKeysFile .ssh/authorized_keys//看看是不是变成autorized_keys
- 如果找不到对应字段就不用管了。
6.2 设置两台cslave的ssh配置
- (1)把公钥复制所有cslave机器上
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器ip:~/
1 |
|
(2)在数据节点cslaver主机里面输入命令:
将公钥复制给authorized_keys
(要在根目录下执行,因为刚刚公钥是复制到根目录下面的。)1
2cd #进入到根目录
cp id_rsa.pub ~/.ssh/authorized_keys
(如果提示没有.ssh目录的话可能是系统一开始没有自动创建这个目录,那就执行ssh-keygen -t rsa 和 cp id_rsa.pub authorized_keys 顺带设置自己免密登陆,就会有那个.ssh目录了)
(3)测试是否可行
在cmaster主机上输入命令(ssh 后面是cslaver的IP地址或者设置了映射的直接输入cslaver1或者cslaver2):
1 |
|
(4)数据节点cslaver设置本机登陆免密
然后切换路径并使用ssh-keygen生成密钥,并将密钥加入到授权中(如提示 bash: cd: adasd: No such file or directory 请执行一次ssh localhost
1 |
|
- 最后执行 cat ./id_rsa.pub >> ./authorized_keys 加入授权(后面没有任何的提示)
1 |
|
其他数据节点主机均这样设置。
如果设置免密登陆失败,请参考:ssh免密登陆配置失败解决办法
7.启动Hadoop
- (1)首先进入到你的hadoop安装路径(我的hadoop安装路径是/usr/local/hadoop),再格式化主节点命名空间,使用命令:
1 |
|
- 方法1:其次在主节点上启动存储服务和资源管理主服务。使用命令:
1 |
|
最后在从节点上启动存储从服务和资源管理从服务(以下两条命令要在两台机器上分别履行)
1 |
|
- 方法2:或进入sbin目录
1 |
|
(启动时如果出现找不到JAVA_HOME,请参考:hadoop启动找不到java-点击打开)
(有时出问题之后namenode或datanode有一个会打不开,这个问题请参考:hadoop节点无法启动-点击打开)
- 服务启动后在3台机器上分别使用jps命令查看是不是启动(主机只需要启动namenode节点,其他的启动datanode节点)。
- 在cmaster主机启动名称节点,在其他节点启动datanode。效果如下图:
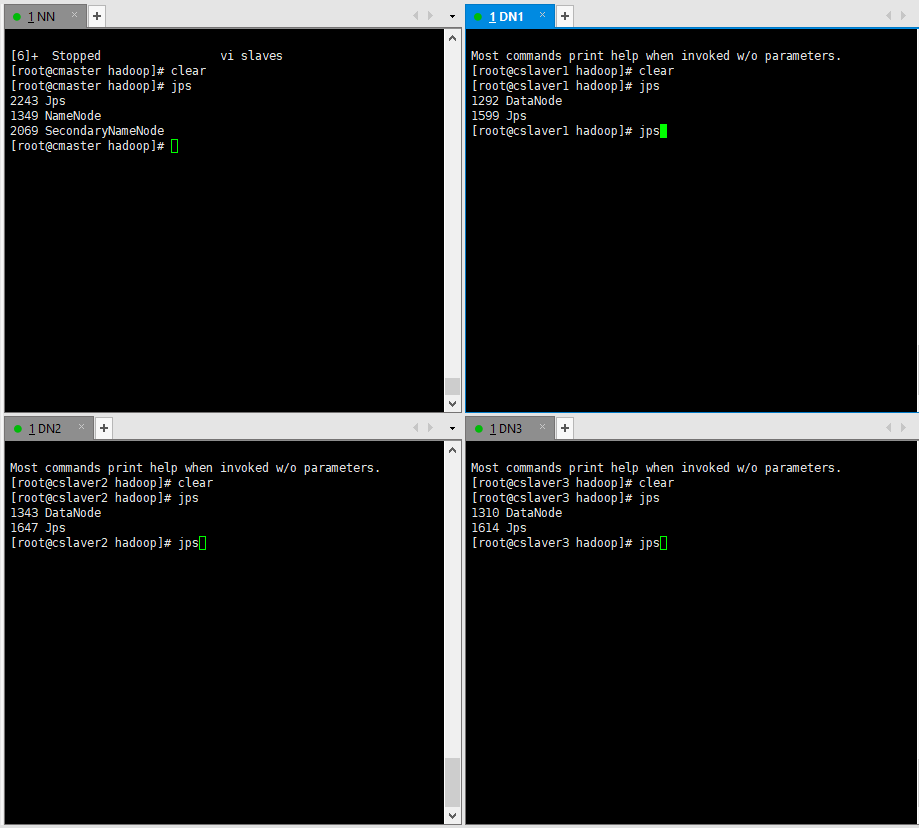
- 启动之后我们还可以在主节点(namenoded)查看所有主节点和主节点控制下的节点的状态
- 命令:
1
hdfs dfsadmin -report | more #节点状态详细信息
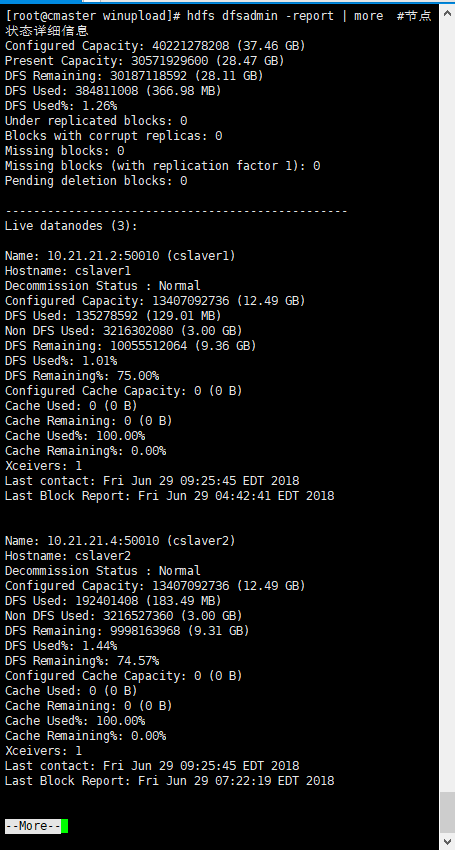
- 这里使用root用户来配置的hadoop环境,用root操作hadoop系统的话容易误操作而造成不可弥补的错误。如果需要使用hadoop用户操作hadoop集群,则后续将相关文件夹所有者改为hadoop即可,后面可能会出现ssh失效的问题,这可能是文件夹权限需要更改,参考:ssh失效-点击打开 参考最后几行修改下权限即可。
8.windows 下eclipse配置hadoop开发环境
参考下面链接
windows 下eclipse配置hadoop开发环境
9.程序&实例
在master上执行hdfs文件操作:使用Linux命令实现hdfs文件操作
Demo程序参考:第一个hdfs程序
java对hdfs的操作Demo:java对hdfs文件的操作
